Bryan de Oliveira
 Hi! I'm Bryan, a 29-year-old AI researcher and PhD Student in Computer Science at the Federal University of Goiás (UFG), based in Goiânia, Brazil. I work at CEIA and AKCIT, where I lead interdisciplinary research teams at the intersection of Deep Reinforcement Learning and decision-making under uncertainty.
Hi! I'm Bryan, a 29-year-old AI researcher and PhD Student in Computer Science at the Federal University of Goiás (UFG), based in Goiânia, Brazil. I work at CEIA and AKCIT, where I lead interdisciplinary research teams at the intersection of Deep Reinforcement Learning and decision-making under uncertainty.
My work centers on agents that make good decisions under uncertainty — combining Deep RL, information-seeking behavior, and Bayesian methods. At AKCIT, I lead research on two main fronts: how agents can reason and act under uncertainty across different abstraction levels, from language models seeking information through dialogue to embodied agents planning in physical environments; and the empirical and theoretical foundations of modern RL algorithms. I also lead a team working on autonomous humanoid robots, covering teleoperation and sim-to-real transfer. Through CEIA, I additionally lead applied R&D with industry partners across energy, finance, and software development.
My research expertise spans Deep Reinforcement Learning, representation learning, world models, and autonomous decision-making. I have proven ability to structure and execute complex R&D projects from conception to publication, complemented by extensive engineering experience in developing and deploying ML systems at scale. This background provides unique insights into both the theoretical foundations and practical constraints of AI systems.
I'm deeply interested in the fundamental questions of artificial intelligence and neuroscience — particularly how we can develop AI systems that learn better representations and world models to effectively plan and adapt in uncertain environments. I believe in a principled, interdisciplinary approach to AI research that combines theory with rigorous empirical validation and real-world impact.
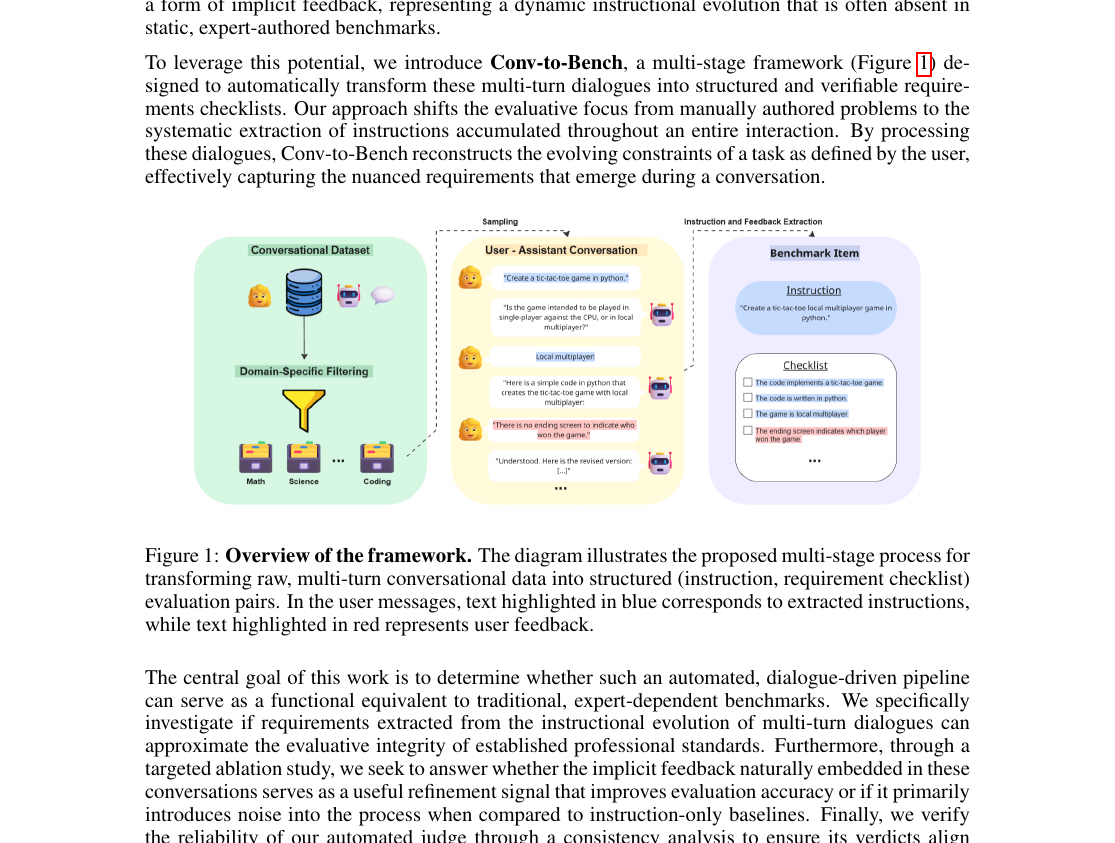
CONV-TO-BENCH: Evaluating Language Models via User–Assistant Dialogues in Code Tasks
ICLR 2026 — DATA-FM Workshop · April 2026 Benchmark DesignCONV-TO-BENCH creates evaluation benchmarks from raw user–assistant interaction logs in code tasks, enabling model assessment on realistic multi-turn dialogue data.
Partial Reasoning in Language Models: Search and Refinement Guided by Uncertainty
AAAI 2026 — LaCATODA Workshop · January 2026 RL under UncertaintyWe propose partial reasoning in language models guided by uncertainty, using search and refinement to selectively truncate chain-of-thought while preserving performance.
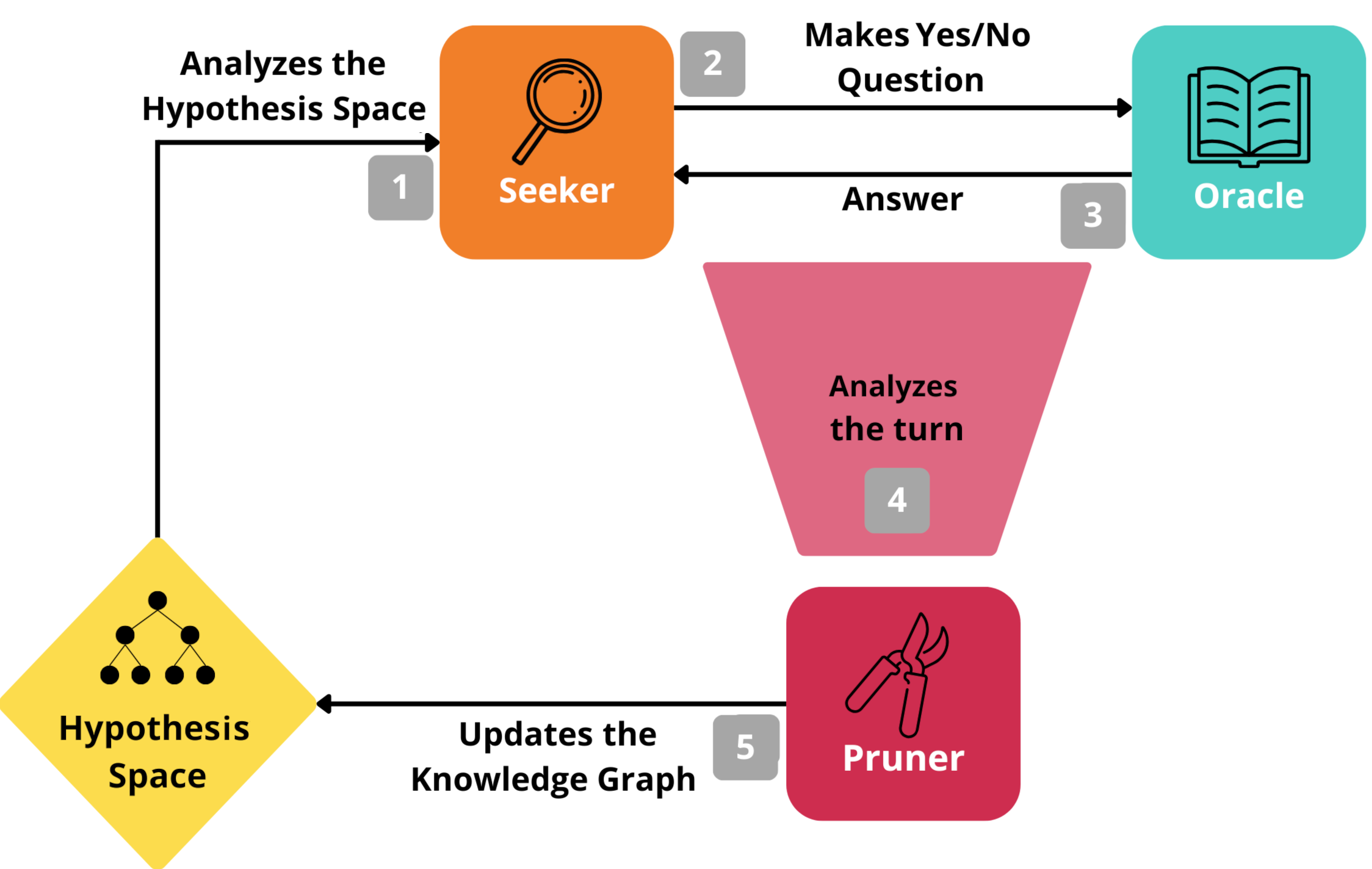
Do Reasoning Models Ask Better Questions? A Formal Information-Theoretic Analysis on Multi-Turn LLM Games
AAAI 2026 — NeusymBridge Workshop · January 2026 RL under UncertaintyA formal information-theoretic analysis on multi-turn LLM games evaluating whether reasoning models ask better questions than standard models.
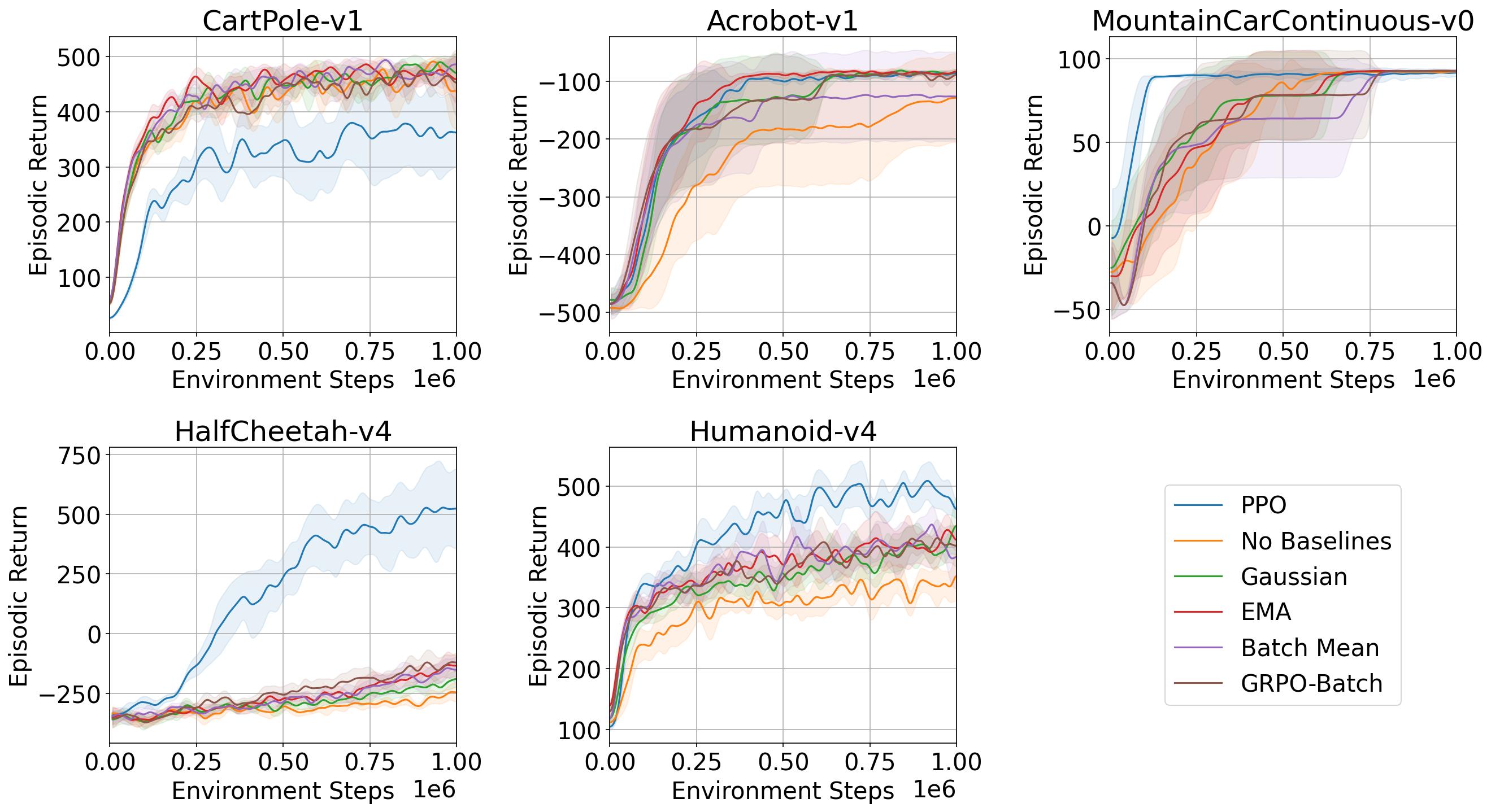
Learning Without Critics? Revisiting GRPO in Classical Reinforcement Learning Environments
NeurIPS 2025 — LatinX in AI Workshop · November 2025 RL FundamentalsTheoretical and empirical study revisiting GRPO in classical RL environments, comparing it against PPO and analyzing the role of the critic.
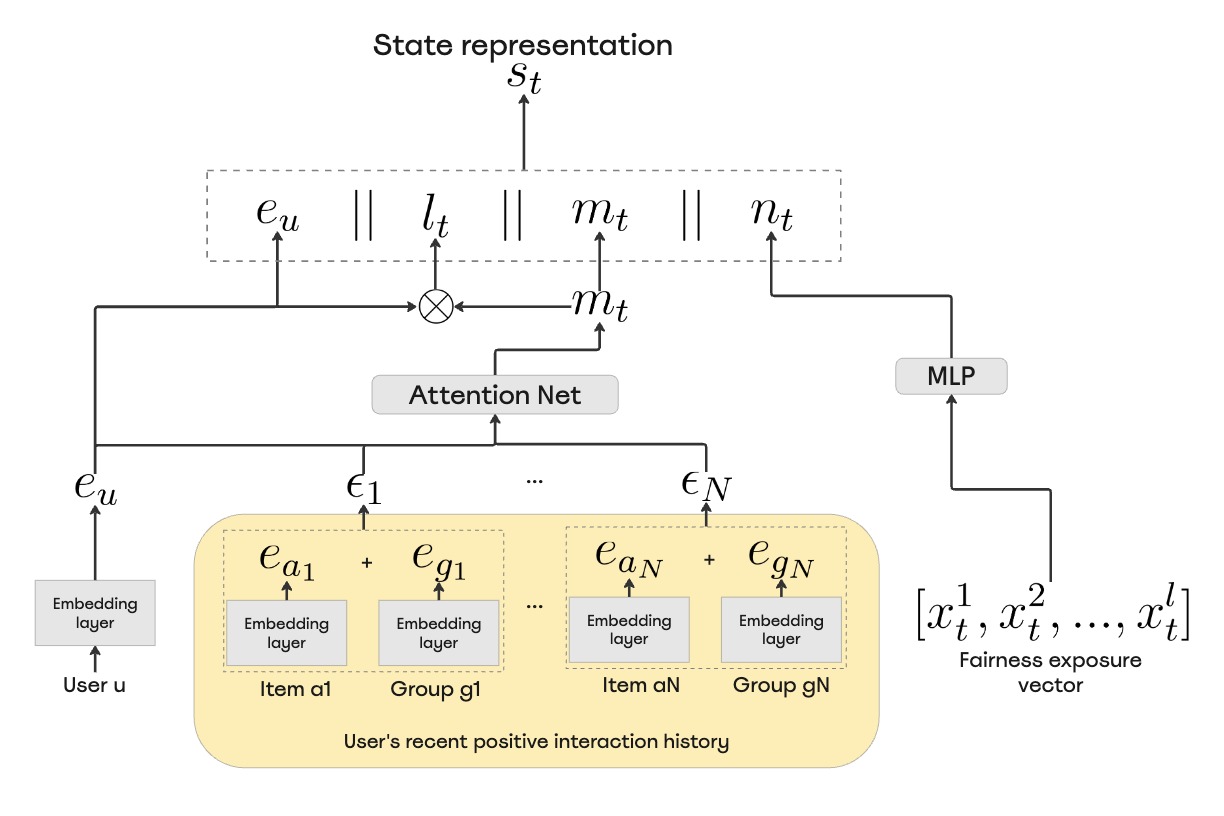
Personalizing Fairness: Adaptive RL with User Diversity Preference for Recommender Systems
RLC 2025 — Workshop on Practical Insights into RL for Real-World Systems · August 2025 Applied RLWe propose an adaptive RL approach for recommender systems that personalizes fairness based on user diversity preferences.
Reinforcement Learning for Debt Pricing: A Case Study in Financial Services
RLC 2025 — Workshop on Practical Insights into RL for Real-World Systems · June 2025 Applied RLOffline RL with LTV-based rewards and bandit orchestration at a large financial institution improved collection values.
Sliding Puzzles Gym: A Scalable Benchmark for State Representation in Visual Reinforcement Learning
ICML 2025 (Proceedings of Machine Learning Research) · May 2025 RL FundamentalsSPGym extends the 8-tile puzzle to evaluate RL agents by scaling representation learning complexity while keeping environment dynamics fixed, revealing opportunities for advancing representation learning for decision-making research.

InfoQuest: Evaluating Multi-Turn Dialogue Agents for Open-Ended Conversations with Hidden Context Oral
RLC 2025 — RLBrew Workshop · March 2025 RL under UncertaintyA benchmark for evaluating how LLMs handle ambiguous open-ended requests through dialogue, revealing that current models struggle to ask effective clarifying questions.

PulseRL: Enabling Offline Reinforcement Learning for Digital Marketing Systems via Conservative Q-Learning Oral
NeurIPS 2021 — 2nd Offline RL Workshop (Oral) · October 2021 Applied RLPulseRL is an offline reinforcement learning system for optimizing communication channels in Digital Marketing Systems (DMS) using Conservative Q-Learning (CQL). It learns from historical data, avoiding costly interactions, and reduces bias from out-of-distribution actions. PulseRL outperformed RL baselines in real-world DMS experiments, proving its effectiveness at scale.
