Bone Age Regression
This is my code for the I2A2 Bone Age Regression competition. I learned a lot by building this pipeline from scratch and experimenting with different model architectures and optimizers. This was my first end-to-end image regression model, and it was very nice seeing my theoretical knowledge work in practice.
This is my code for the I2A2 Bone Age Regression competition. I learned a lot by building this pipeline from scratch and experimenting with different model architectures and optimizers. This was my first end-to-end image regression model, and it was very nice seeing my theoretical knowledge work in practice.
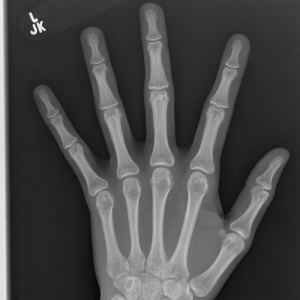
This competition was inspired by RSNA's Bone Age challenge, in which given hand X-ray images, the model should predict the patient's bone age.



X-ray images provided in the competition's dataset.
My final solution used a ResNet50 architecture, a Rectified Adam optimizer and geometric data augmentations. This model achieved a Mean Average Error of 13.2 after 20 epochs of training, which I believe could be improved given more training time and a better preprocessing pipeline (e.g. using object detection to segment the hands and normalizing hand rotation). Unfortunately, I didn't save all the hyperparameters I experimented with (neither their results), but you'll find the ones I used for my last submission in the code.
I used tensorboard to log the training curves and tqdm to track progress. I also used FCMNotifier, a tool I made to send logs as notifications to my phone.
Requirements
See requirements.txt.
Usage
- Download the requirements with
pip install -r requirements.txt - Download the dataset and sample submission with
sh download_data.sh. You may need to log in with your Kaggle account in order to do it. - Train the ResNet50 model with
python boneage.py - Try different models and hyperparameters by editing the training script or use the
boneage.ipynbnotebook to do it interactively.
Credits
I used the vision models already implemented in torchvision with slight changes. You can try other torchvision models by adding the in_channels parameter to generalize the number of input channels since torchvision models work with RGB images.