PulseRL: Enabling Offline Reinforcement Learning for Digital Marketing Systems via Conservative Q-Learning
PulseRL is an offline reinforcement learning system for optimizing communication channels in Digital Marketing Systems (DMS) using Conservative Q-Learning (CQL). It learns from historical data, avoiding costly interactions, and reduces bias from out-of-distribution actions. PulseRL outperformed RL baselines in real-world DMS experiments, proving its effectiveness at scale.

Abstract
Digital Marketing Systems (DMS) are the primary point of contact between a digital business and its customers. In this context, the communication channel optimization problem poses a precious and still open challenge for DMS. Due to its interactive nature, Reinforcement Learning (RL) appears as a promising formulation for this problem. However, the standard RL setting learns from interacting with the environment, which is costly and dangerous for production systems. Furthermore, it also fails to learn from historical interactions due to the distributional shift between the collection and learning policies. For this matter, we present PulseRL, an offline RL-based production system for communication channel optimization built upon the Conservative Q-Learning (CQL) Framework. PulseRL architecture comprises the whole engineering pipeline (data processing, training, deployment, and monitoring), scaling to handle millions of users. Using CQL, PulseRL learns from historical logs, and its learning objective reduces the shift problem by mitigating the overestimation bias from out-of-distribution actions. We conducted experiments in a real-world DMS. Results show that PulseRL surpasses RL baselines with a significant margin in the online evaluation. They also validate the theoretical properties of CQL in a complex scenario with high sampling error and non-linear function approximation.
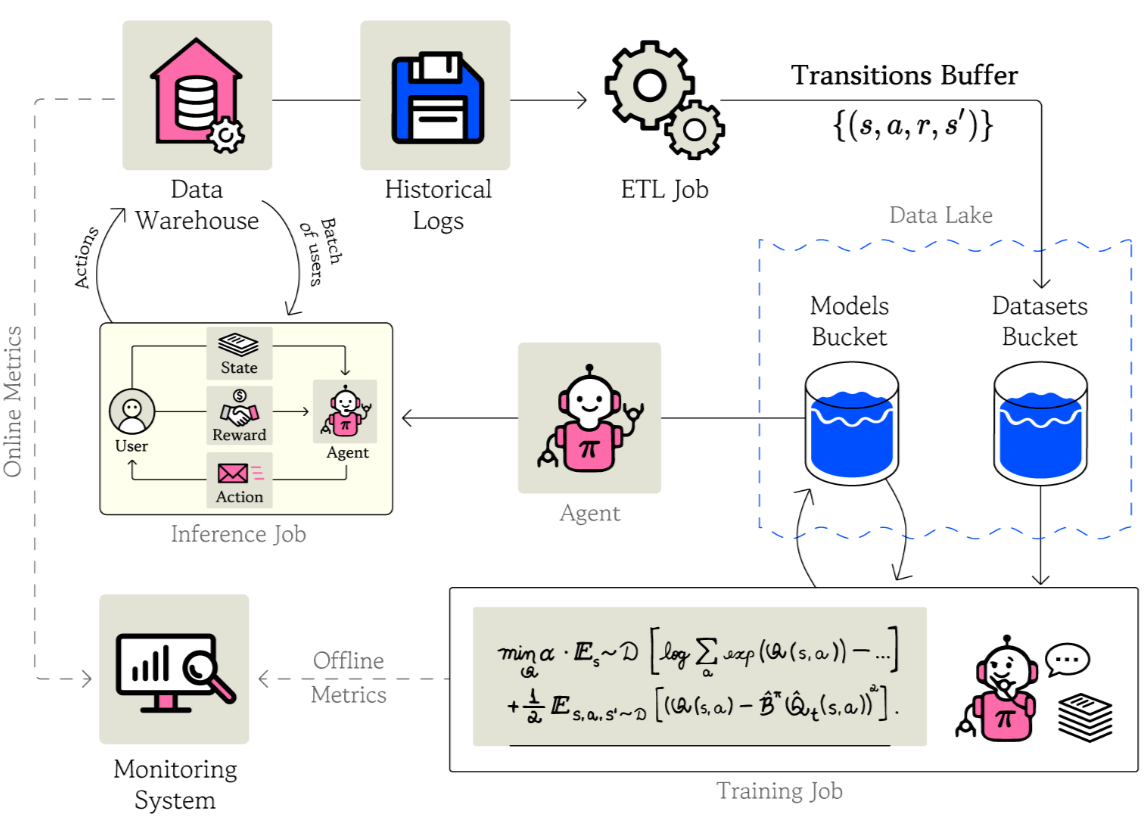
Illustration of PulseRL’s system pipeline. We compose it with different big data storage models, a data transformation engine, a task manager, and specialized microservices for training and inference, which ensures scalability for handling millions of users on a daily basis. It also provides version control for source code, dataset, MDP’s and RL agents.
Presentation at the 2nd Offline Reinforcement Learning Workshop at the 35th Conference on Neural Information Processing (NeurIPS 2021).