Sliding Puzzles Gym: A Scalable Benchmark for State Representation in Visual Reinforcement Learning
SPGym extends the 8-tile puzzle to evaluate RL agents by scaling representation learning complexity while keeping environment dynamics fixed, revealing opportunities for advancing representation learning for decision-making research.

Abstract
Effective visual representation learning is crucial for reinforcement learning (RL) agents to extract task-relevant information from raw sensory inputs and generalize across diverse environments. However, existing RL benchmarks lack the ability to systematically evaluate representation learning capabilities in isolation from other learning challenges. To address this gap, we introduce the Sliding Puzzles Gym (SPGym), a novel benchmark that transforms the classic 8-tile puzzle into a visual RL task with images drawn from arbitrarily large datasets. SPGym's key innovation lies in its ability to precisely control representation learning complexity through adjustable grid sizes and image pools, while maintaining fixed environment dynamics, observation, and action spaces. This design enables researchers to isolate and scale the visual representation challenge independently of other learning components. Through extensive experiments with model-free and model-based RL algorithms, we uncover fundamental limitations in current methods' ability to handle visual diversity. As we increase the pool of possible images, all algorithms exhibit in- and out-of-distribution performance degradation, with sophisticated representation learning techniques often underperforming simpler approaches like data augmentation. These findings highlight critical gaps in visual representation learning for RL and establish SPGym as a valuable tool for driving progress in robust, generalizable decision-making systems.
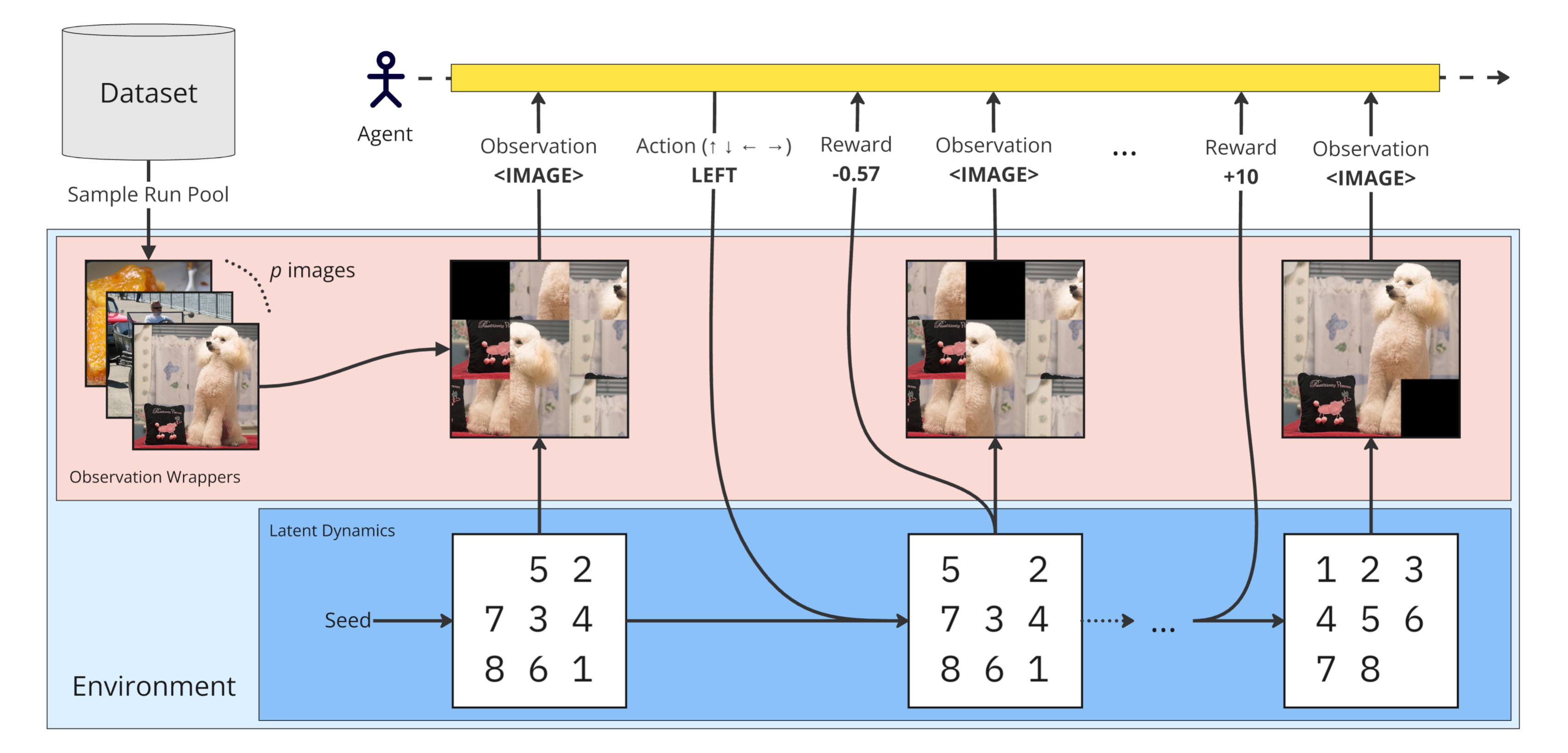
Overview of the Sliding Puzzles Gym (SPGym). The framework extends the 8-tile puzzle by replacing numbered tiles with image patches. At each training run, SPGym samples a pool of images and, at each episode, it randomly selects one of those images to form the observations. While we scale visual diversity by adjusting the pool size, the task and environment dynamics remain fixed.
Poster at the 42nd International Conference on Machine Learning (ICML).